R과 바이탈(vitals)로 최적의 LLM을 선택하는 방법

컨텐츠 정보
- 조회 2,366
본문
생성형 AI 애플리케이션이 기대한 답변을 내놓고 있는가? 더 저렴한 LLM, 혹은 로컬에서 무료로 실행할 수 있는 모델로도 일부 작업을 충분히 처리할 수 있을까?
이 같은 질문에 답하기는 쉽지 않다. 모델 성능은 매달 달라지는 듯 보인다. 기존 소프트웨어 코드와 달리 LLM은 같은 질문에도 매번 동일한 답을 내놓지 않는다. 테스트를 반복 실행하는 과정은 번거롭고 시간도 많이 든다.
다행히 LLM 테스트를 자동화하는 프레임워크가 있다. 이런 LLM 평가 체계는 전통적인 코드의 유닛 테스트와 비슷한 개념이다. 다만 차이가 있다. LLM은 같은 질문에 여러 방식으로 답할 수 있고, 정답이 하나가 아닐 수 있다. 단순히 특정 값과 일치하는지 확인하는 방식으로는 충분하지 않다. 훨씬 더 유연한 기준으로 응답을 분석해야 한다.
파이썬의 인스펙트(Inspect) 프레임워크를 기반으로 한 R 패키지 ‘바이탈(vitals)’은 이러한 자동화된 LLM 평가 체계를 R 환경에 제공한다. vitals은 R 패키지 엘머(ellmer)와 연동하도록 설계됐다. 두 패키지를 함께 사용하면 프롬프트와 AI 애플리케이션을 평가하고, 서로 다른 LLM이 성능과 비용에 어떤 영향을 미치는지 비교할 수 있다. 패키지 저자인 포짓(Posit)의 수석 소프트웨어 엔지니어 사이먼 카우치는 이메일을 통해, vitals 평가 세트인 ‘블러프벤치(bluffbench)’를 활용한 실험에서 흥미로운 결과가 나왔다고 밝혔다. 해당 실험은 AI 에이전트가 기대와 어긋나는 정보가 그래프에 포함될 경우 이를 무시하는 경향이 있다는 점을 보여줬다. 카우치는 이 결과가 “일부 사용자에게는 큰 반향을 일으켰다”라고 전했다.
카우치는 현재 vitals을 활용해 어떤 LLM이 R 코드를 얼마나 잘 작성하는지도 측정하고 있다.
vitals 설정
vitals 패키지는 CRAN에서 설치할 수 있다. 개발 버전을 사용하려면 깃허브에서 pak::pak("tidyverse/vitals")로 설치하면 된다. 이 글 작성 시점 기준으로, 예제에서 사용하는 일부 기능, 특히 텍스트에서 구조화된 데이터를 추출하는 전용 함수는 개발 버전에서만 제공된다.
vitals은 Task 객체를 사용해 LLM 평가를 생성하고 실행한다. 각 Task에는 세 가지 요소가 필요하다. 데이터셋(dataset), 솔버(solver), 스코어러(scorer)다.
데이터셋
dataset은 테스트하려는 내용을 담은 데이터 프레임이다. 이 데이터 프레임에는 최소 두 개의 열이 필요하다.
input: LLM에 보낼 요청target: LLM이 응답하기를 기대하는 내용
vitals 패키지에는 are라는 예제 데이터셋이 포함돼 있다. 이 데이터 프레임에는 id 같은 추가 열도 들어 있다. id는 데이터에 포함해두면 유용하지만 필수는 아니다.
카우치는 몇 달 전 포짓 컨퍼런스에서, 자신만의 input-target 쌍을 만드는 가장 쉬운 방법 중 하나는 스프레드시트를 활용하는 것이라고 설명했다. 스프레드시트에 input과 target 열을 만든 뒤 원하는 내용을 입력하고, googlesheets4나 rio 같은 패키지를 이용해 해당 파일을 R로 불러오면 된다.

input과 target 열을 사용해 vitals 데이터셋을 만드는 스프레드시트 예시Foundry
아래는 vitals을 테스트하기 위해 사용할 3가지 간단한 질의에 대한 R 코드다. 그대로 복사해 실행할 수 있도록 R 데이터 프레임을 직접 생성하는 방식으로 작성했다. 이 데이터셋은 LLM에 막대그래프용 R 코드 작성, 특정 텍스트의 감성 판단, 하이쿠 생성 등을 요청한다.
my_dataset This desktop computer has a better processor and can handle much more demanding tasks such as running LLMs locally. However, itU{2019}s also noisy and comes with a lot of bloatware.", "Write me a haiku about winter" ), target = c( 'Example solution: ```library(ggplot2)rnlibrary(scales)rnsample_data 다음으로 라이브러리를 불러오고, 평가를 실행할 때 사용할 로그 디렉토리를 설정한다. vitals은 패키지를 로드하면 로그 디렉토리를 지정하라고 안내한다.
library(vitals)library(ellmer)vitals_log_dir_set("./logs")아래 코드는 해당 데이터셋으로 새로운 Task를 설정하는 시작 단계다. 다만 필수 인자인 solver와 scorer를 함께 지정하지 않으면 오류가 발생한다.
my_task 이미 준비된 예제를 사용하고 싶다면, 7개의 R 작업이 포함된 dataset = are를 활용할 수 있다.
적절한 target 예시를 만드는 일은 생각보다 공이 많이 든다. 감성 분류 예제는 ‘mixed’처럼 한 단어 응답을 기대했기 때문에 비교적 단순했다. 그러나 코드 작성이나 텍스트 요약처럼 자유도가 높은 질의는 응답 형태가 다양하다. 이 단계는 서두르지 않는 것이 좋다. 자동화된 ‘평가자’가 정확히 채점하려면, 허용 가능한 응답 기준을 세심하게 설계해야 한다.
솔버
Task의 두 번째 구성 요소는 solver다. solver는 질의를 LLM에 전달하는 R 코드다. 단순한 질의라면 보통 ellmer의 채팅 객체를 vitals의 generate() 함수로 감싸는 방식으로 충분하다. 반면 도구 호출이 필요하거나 입력 구조가 복잡하다면 사용자 정의 solver를 작성해야 할 수 있다. 이번 데모에서는 기본 generate() 기반 solver를 사용한다. 이후에는 generate_structured()를 활용한 두 번째 solver도 추가할 예정이다.
vitals을 사용할 때는 R 패키지 ellmer에 대한 이해가 도움이 된다. 아래는 vitals 없이 ellmer만 사용하는 예시다. 데이터 프레임 my_dataset의 첫 번째 질의인 my_dataset$input[1]을 프롬프트로 전달한다. 이 코드는 LLM의 응답을 반환하지만, 해당 응답을 평가하지는 않는다.
참고로 이 코드를 그대로 실행하려면 오픈AI API 키가 필요하다. 또는 ellmer가 지원하는 다른 LLM 업체의 모델과 API 키로 변경해도 된다. 다른 업체를 사용할 경우 필요한 API 키를 미리 저장해둬야 한다. 여기서는 오픈AI의 현재 최저가 모델인 GPT-5 나노(nano)를 사용했다.
my_chat 이렇게 생성한 my_chat이라는 ellmer 채팅 객체를 generate() 함수로 감싸면 vitals용 solver로 사용할 수 있다.
# This code won't run yet without the tasks's third required argument, a scorermy_task Task 객체는 데이터셋의 input 열을 LLM에 전달할 질문으로 자동 인식한다. 데이터셋에 질의가 여러 개 포함돼 있다면 generate()가 이를 순차적으로 처리한다.
스코어러
마지막으로 필요한 요소는 scorer다. 이름 그대로 결과를 채점하는 역할을 한다. vitals에는 여러 유형의 scorer가 포함돼 있다. 이 가운데 두 가지는 LLM을 활용해 결과를 평가하는 방식으로, 흔히 ‘LLM을 심판으로 활용’한다고 표현한다.
vitals의 LLM 기반 scorer 중 하나인 model_graded_qa()는 solver가 질문에 얼마나 적절히 답했는지를 평가한다. 또 다른 함수인 model_graded_fact()는 문서에 따르면 “solver의 응답에 특정 사실이 포함돼 있는지 판단”한다. 이 밖에도 detect_exact()나 detect_includes()처럼 문자열 패턴을 기준으로 점수를 매기는 방식도 제공한다.
일부 연구는 LLM이 결과 평가에서도 비교적 준수한 성능을 보인다고 보고한다. 다만 생성형 AI와 관련된 대부분의 작업이 그렇듯, 필자는 사람의 검토 없이 LLM 평가만을 전적으로 신뢰하지는 않는다.
실무 팁도 있다. 평가 대상이 되는 모델이 소형이거나 성능이 낮다면, 같은 모델로 채점까지 맡기는 것은 바람직하지 않다. vitals은 기본적으로 테스트 중인 동일한 LLM을 scorer로 사용하지만, 별도의 LLM을 심판으로 지정할 수 있다. 채점 기준이 단순하지 않다면, 상위권 프런티어 LLM을 심판 역할로 사용하는 편이 안전하다.
예를 들어 model_graded_qa()의 scorer로 클로드 소네트를 사용하는 문법은 다음과 같다.
scorer = model_graded_qa(scorer_chat = chat_anthropic(model = "claude-sonnet-4-6"))이 scorer는 기본적으로 partial_credit = FALSE로 설정돼 있다. 즉, 응답이 100% 정확하지 않으면 오답으로 처리한다. 다만 작업 특성상 부분 점수를 허용하는 편이 적절하다면, partial_credit = TRUE 인자를 추가해 부분 점수를 인정하도록 설정할 수 있다.
scorer = model_graded_qa(partial_credit = TRUE, scorer_chat = chat_anthropic(model = "claude-sonnet-4-6"))필자는 scorer로 소네트 4.5를 사용했고, 부분 점수는 허용하지 않았다. 그 결과 한 항목에서 오채점이 발생했다. 막대그래프용 R 코드가 대부분의 요구 사항을 충족했지만, 값을 내림차순으로 정렬하지 않았음에도 정답으로 처리됐다. 최근 출시된 소네트 4.6도 시험해봤지만, 이 모델 역시 한 항목에서 잘못된 채점을 했다.
오퍼스 4.6은 소네트보다 성능이 뛰어나지만 비용도 더 높다. 입력 토큰 100만 개당 5달러, 출력 토큰 100만 개당 25달러로, 소네트보다 약 67% 비싸다. 어떤 모델과 업체를 선택할지는 테스트 규모, 특정 LLM이 작업을 얼마나 잘 이해하는지에 대한 신뢰도(클로드는 R 코드 작성에 강점이 있다는 평가를 받는다), 그리고 과제를 얼마나 정확하게 평가해야 하는지 등에 따라 달라진다. 비용이 부담된다면 사용량을 꾸준히 확인하는 것이 좋다.
비용이 부담된다면 사용량을 꾸준히 확인하는 것이 좋다. 이 튜토리얼 예제를 따라 하면서 비용을 지출하고 싶지 않고, 다소 성능이 낮은 LLM을 사용해도 괜찮다면 무료 등급을 제공하는 깃허브 모델(GitHub Models)을 고려해볼 수 있다. ellmer는 chat_github()로 깃허브 모델을 지원한다. 사용 가능한 LLM 목록은 models_github()를 실행해 확인할 수 있다.
아래 예제에서는 my_task에 model_graded_qa() 기반 채점을 추가하고, Task에 이름도 지정했다. 다만 이후 다른 모델을 시험하기 위해 Task를 복제할 계획이라면 이름을 지정하지 않는 편이 낫다. 복제된 Task는 원래 이름을 그대로 유지하며, 이 글 작성 시점 기준으로는 이를 변경할 방법이 없다.
my_task 이제 Task를 실행할 준비가 끝났다.
첫 Task 실행하기
Task는 Task 객체의 $eval() 메서드로 실행한다.
my_task$eval()$eval() 메서드는 내부적으로 다섯 가지 메서드를 순차적으로 실행한다. $solve(), $score(), $measure(), $log(), $view()가 그것이다. 실행이 끝나면 내장 로그 뷰어가 자동으로 열린다. 화면에 표시된 하이퍼링크 형태의 Task 이름을 클릭하면 보다 상세한 실행 결과를 확인할 수 있다.
 vitals의 내장 뷰어에서 확인할 수 있는
vitals의 내장 뷰어에서 확인할 수 있는 Task 실행 상세 화면. 각 샘플을 클릭하면 추가 정보를 볼 수 있다.Foundry
여기서 “C”는 정답(Correct), “I”는 오답(Incorrect)을 의미한다. 부분 점수를 허용했다면 “P”(Partially correct)도 표시됐을 것이다.
나중에 다시 로그를 확인하고 싶다면 vitals_view("your_log_directory")로 내장 뷰어를 호출할 수 있다. 로그 파일은 JSON 형식으로 저장되기 때문에 다른 도구로 열어볼 수도 있다.
LLM의 신뢰성을 판단하려면 평가를 한 번만 실행하기보다는 여러 차례 반복하는 편이 좋다. 단순히 우연히 정답을 맞혔을 가능성을 배제하기 위해서다. 여러 번 실행하려면 epochs 인자를 설정하면 된다.
my_task$eval(epochs = 10)10번의 epoch를 실행한 한 차례 테스트에서 막대그래프 코드의 정확도는 70%였다. 이것이 ‘충분히 좋은’ 수준인지 여부는 상황에 따라 다르다. 다른 실행에서는 정확도가 90%까지 올라가기도 했다. 특히 매번 100%를 기록하지 않는 모델이라면, 실제 성능을 제대로 파악하려면 충분한 표본 수가 필요하다. 테스트 횟수가 적으면 오차 범위가 상당히 커질 수 있다. (vitals 결과의 통계 분석을 자세히 알고 싶다면 패키지의 analysis vignette를 참고하면 된다.)
세 개 질의를 대상으로 총 11회 epoch를 실행했을 때, 채점 모델로 소네트 4.6을 사용하면 약 0.14달러가 들었고, 오퍼스 4.6을 사용하면 약 0.27달러가 들었다. 다만 모든 질의에 LLM 기반 평가가 필요했던 것은 아니다. 예제를 여러 Task 객체로 나눴다면 일부는 더 단순한 방식으로 채점할 수 있었다. 예를 들어 감성 분석은 “Mixed”라는 단어를 확인하는 비교적 단순한 평가였다.
vitals에는 Task 평가 결과를 데이터 프레임으로 정리해주는 함수도 포함돼 있다. my_task$get_samples()를 실행하면 된다. 이 형식이 마음에 든다면, Task 객체가 R 세션에 존재하는 동안 데이터 프레임을 저장해두는 것이 좋다.
results_df Task 객체 자체도 함께 저장해두는 것이 좋다.
입력 질의를 실행하는 도중 API 오류가 발생하면 전체 실행이 실패한다. epoch를 많이 설정해 대규모 테스트를 진행할 계획이라면, 토큰과 시간을 낭비하지 않도록 여러 번에 나눠 실행하는 편이 안전하다.
다른 LLM으로 교체하기
동일한 Task를 다른 모델로 실행하는 방법은 여러 가지다. 먼저 해당 모델을 사용하는 새로운 채팅 객체를 생성한다. 예를 들어 구글 제미나이 3 플래시 프리뷰를 테스트하려면 다음과 같은 코드를 사용할 수 있다.
my_chat_gemini 그다음에는 3가지 방법 중 하나로 Task를 실행할 수 있다.
- 기존
Task를 복제한 뒤,$set_solver()를 사용해 새 채팅 객체를solver로 지정한다.
my_task_gemini - 기존
Task를 복제한 뒤, 실행 시점에 새 채팅 객체를solver로 지정해 실행한다.
my_task_gemini - 처음부터 새로운
Task를 생성한다. 이렇게 하면 새 이름도 함께 지정할 수 있다.
my_task_gemini 테스트하려는 LLM 업체의 API 키를 미리 설정해두어야 한다. 다만 올라마(ollama)로 로컬 LLM을 실행하는 경우처럼 API 키가 필요 없는 플랫폼을 사용하는 경우는 예외다.
여러 Task 실행 결과 보기
여러 모델로 Task를 실행했다면 vitals_bind() 함수를 사용해 결과를 하나로 합칠 수 있다.
both_tasks 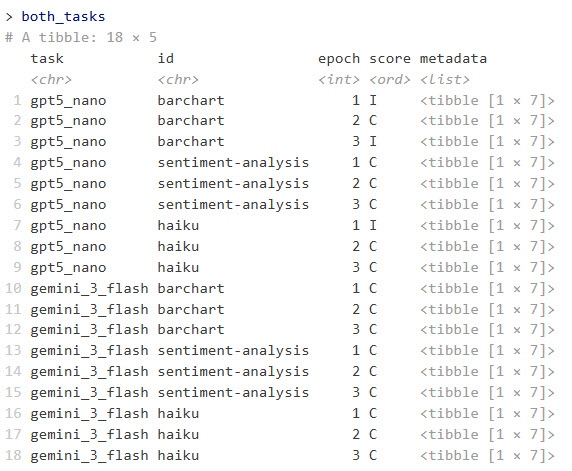 각 LLM을 3회 반복 실행한 뒤 결합한
각 LLM을 3회 반복 실행한 뒤 결합한 Task 결과 예시Foundry
이 함수는 task, id, epoch, score, metadata 열을 포함한 R 데이터 프레임을 반환한다. metadata 열의 각 행에는 또 다른 데이터 프레임이 들어 있으며, 여기에는 input, target, result, solver_chat, scorer_chat, scorer_metadata, scorer 열이 포함된다.
input, target, result 열을 펼쳐 더 쉽게 살펴보고 분석하기 위해, 필자는 다음과 같이 metadata 열을 언네스트했다.
library(tidyr)both_tasks_wide unnest_longer(metadata) |> unnest_wider(metadata)이후에는 간단한 스크립트를 실행해 각 막대그래프 코드 결과를 순차적으로 확인하고, 실제로 어떤 그래프가 생성되는지 살펴볼 수 있었다.
library(dplyr)# Some results are surrounded by markdown and that markdown code needs to be removed or the R code won't runextract_code filter(id == "barchart")# Loop through each resultfor (i in seq_len(nrow(barchart_results))) { code_to_run 로컬 LLM 테스트하기
vitals의 가장 유용한 활용례는 로컬 LLM 테스트다. 현재 필자의 PC는 GPU 메모리 12GB 환경이라 실행 가능한 모델이 제한적이다. 하지만 소형 모델이 빠르게 발전하고 있는 만큼, 민감한 데이터를 로컬에서 처리하는 작업에도 곧 충분히 활용할 수 있을 것으로 기대한다. vitals은 특정 사용례에 맞춰 새로운 LLM을 손쉽게 테스트할 수 있게 해준다.
vitals은 ellmer를 통해 로컬에서 LLM을 실행하는 대표적 도구인 ollama를 지원한다. ollama를 사용하려면 애플리케이션을 실행한 뒤, 데스크톱 앱이나 터미널에서 명령을 입력하면 된다. 모델을 다운로드하려면 ollama pull 을 실행하고, 모델을 다운로드하면서 채팅을 시작해 정상 동작 여부를 확인하려면 ollama run 을 사용한다. 예를 들어 ollama pull ministral-3:14b와 같이 입력하면 된다.
R 패키지 롤라마(rollama)를 사용하면 R 환경에서도 ollama용 로컬 LLM을 다운로드할 수 있다. 단, ollama가 실행 중이어야 한다. 문법은 rollama::pull_model("model-name")이며, 예를 들어 rollama::pull_model("ministral-3:14b")처럼 사용한다. R이 시스템에서 실행 중인 ollama를 인식하는지 확인하려면 rollama::ping_ollama()를 실행하면 된다.
필자는 구글의 gemma3-12b와 마이크로소프트 phi4도 내려받은 뒤, 앞서 사용한 동일한 데이터셋으로 각각 Task를 생성했다. 참고로 이 글 작성 시점 기준으로, 이름에 콜론(:)이 포함된 LLM을 처리하려면 vitals 개발 버전이 필요하다. 다음 CRAN 버전(0.2.0 이후)에서는 이 문제가 해결될 예정이다.
# Create chat objectsministral_chat 3가지 로컬 LLM 모두 감성 분석에서는 정확한 결과를 냈다. 그러나 막대그래프 과제에서는 모두 성능이 좋지 않았다. 일부 코드는 막대그래프를 생성하긴 했지만, 축을 뒤집고 내림차순으로 정렬하는 요구 사항을 충족하지 못했다. 또 다른 코드는 아예 실행되지 않았다.
 로컬 LLM 5개로 데이터셋을 한 차례 실행한 결과 예시
로컬 LLM 5개로 데이터셋을 한 차례 실행한 결과 예시Foundry
위 결과 테이블을 생성한 R 코드는 다음과 같다.
library(dplyr)library(gt)library(scales)# Prepare the dataplot_data rename(LLM = task, task = id) |> group_by(LLM, task) |> summarize( pct_correct = mean(score == "C") * 100, .groups = "drop" )color_fn tidyr::pivot_wider(names_from = task, values_from = pct_correct) |> gt() |> tab_header(title = "Percent Correct") |> cols_label(`sentiment-analysis` = html("sentiment-
analysis")) |> data_color( columns = -LLM, fn = color_fn )오퍼스를 채점 모델로 사용해 이들 로컬 LLM 실행 결과를 평가하는 데 0.39달러가 들었다. 나쁘지 않은 비용이다.
텍스트에서 구조화된 데이터 추출하기
vitals에는 일반 텍스트에서 구조화된 데이터를 추출하는 전용 함수 generate_structured()가 포함돼 있다. 이 함수는 채팅 객체와 함께, LLM이 반환해야 할 데이터 타입을 명확히 정의해야 한다. 이 글 작성 시점 기준으로 generate_structured()를 사용하려면 vitals의 개발 버전이 필요하다.
먼저 아래는 일반 텍스트 설명에서 주제, 발표자 이름과 소속, 날짜, 시작 시간을 추출하기 위해 만든 새로운 데이터셋이다. 더 복잡한 버전에서는 중앙유럽표준시(CET)를 동부 표준시(ET)로 변환하도록 LLM에 요청한다.
extract_dataset R Package Development in PositronrnThursday, January 15th, 18:00 - 20:00 CET (Rome, Berlin, Paris timezone) rnStephen D. Turner is an associate professor of data science at the University of Virginia School of Data Science. Prior to re-joining UVA he was a data scientist in national security and defense consulting, and later at a biotech company (Colossal, the de-extinction company) where he built and deployed scores of R packages.", "Extract the workshop topic, speaker name, speaker affiliation, date in 'yyyy-mm-dd' format, and start time in Eastern Time zone in 'hh:mm ET' format from the text below. (TZ is the time zone). Assume the date year makes the most sense given that today's date is February 7, 2026. Return ONLY those entities in the format {topic}, {speaker name}, {date}, {start_time}. Convert the given time to Eastern Time if required. R Package Development in PositronrnThursday, January 15th, 18:00 - 20:00 CET (Rome, Berlin, Paris timezone) rnStephen D. Turner is an associate professor of data science at the University of Virginia School of Data Science. Prior to re-joining UVA he was a data scientist in national security and defense consulting, and later at a biotech company (Colossal, the de-extinction company) where he built and deployed scores of R packages." ), target = c( "R Package Development in Positron, Stephen D. Turner, University of Virginia (or University of Virginia School of Data Science), 2026-01-15, 18:00. OR R Package Development in Positron, Stephen D. Turner, University of Virginia (or University of Virginia School of Data Science), 2026-01-15, 18:00 CET.", "R Package Development in Positron, Stephen D. Turner, University of Virginia (or University of Virginia School of Data Science), 2026-01-15, 12:00 ET." ))아래는 ellmer의 type_object() 함수를 사용해 데이터 구조를 정의하는 예시다. 각 인자는 데이터 필드 이름과 해당 타입(예 : string, integer 등)을 지정한다. 여기서는 workshop_topic, speaker_name, current_speaker_affiliation, date(문자열), start_time(문자열)을 추출하도록 설정했다.
my_object 다음으로, 앞서 생성한 채팅 객체를 사용해 새로운 구조화 데이터 Task를 실행한다. 채점 기준이 비교적 단순하기 때문에 심판 역할로는 소네트를 사용한다.
my_task_structured 소네트를 채점 모델로 사용해 2개 질의를 각각 15회씩 평가하는 데 총 0.16달러가 들었다. 결과는 다음과 같다.
 텍스트에서 구조화된 데이터를 추출하는 과제에서 각 LLM의 성능 비교 결과
텍스트에서 구조화된 데이터를 추출하는 과제에서 각 LLM의 성능 비교 결과Foundry
로컬 모델인 젬마가 100%를 기록한 점은 예상 밖이었다. 우연일 가능성을 확인하기 위해 평가를 17회 추가로 실행해 총 20회로 늘렸다. 흥미롭게도 기본 추출 과제 20건 중 2건에서 제목을 “R Package Development in Positron” 대신 “R Package Development”로 반환해 오답 처리됐다. 반면 더 복잡한 과제에서는 100% 정확도를 유지했다. 이 결과를 두고 클로드 오퍼스에 의견을 묻자, ‘더 쉬운’ 과제가 오히려 성능이 낮은 모델에는 더 모호하게 해석됐을 수 있다는 답을 내놨다. 지시 사항을 가능한 한 구체적으로 작성해야 한다는 교훈을 얻었다.
그럼에도 젬마의 이번 성과는 실제 엔티티 추출 작업에도 적용해볼 만한 수준이었다. 여러 로컬 LLM을 대상으로 자동화된 평가를 실행하지 않았다면 이런 가능성을 확인하기 어려웠을 것이다.
결론
항상 예측 가능하고 동일한 결과를 반환하는 코드를 작성해왔다면, 실행할 때마다 다른 답을 내놓는 스크립트는 불안하게 느껴질 수 있다. LLM의 다음 응답을 완전히 예측할 수 있는 방법은 없다. 그러나 수동으로 그때그때 질의를 던져 확인하는 대신, 측정 가능한 결과를 바탕으로 구조화된 테스트를 반복 실행하면 코드에 대한 신뢰도를 높일 수 있다.
모델 생태계가 빠르게 변화하는 상황에서 단순한 범용 벤치마크가 아니라 자신에게 중요한 실제 작업을 기준으로 최신 LLM의 성능을 점검하는 일도 가능하다. 평가 체계를 갖추면 변화 속에서도 보다 근거 있는 선택을 할 수 있다.
dl-itworldkorea@foundryco.com
관련자료
-
링크
-
이전
-
다음






